Introduction to Pandas#
What you will learn in this lesson:
What is Pandas
How to import Pandas
Create series and dataframes
A first glimpse to dataframes’ attributes and methods.
What is Pandas?#
Pandas is a fundamental data manipulation library in Python, widely used in data science and analytics.
It provides two key data structures:
Series: A one-dimensional labeled array capable of holding any data type.
DataFrame: A two-dimensional labeled data structure with columns that can contain different types of data.
By far, the most important data structure in Pandas (and R) is the dataframe. In most data science applications, we work with tabular data where rows represent observations and columns represent features. Effective data manipulation is critical for preparing clean and useful datasets for analysis, and this is where Pandas (or R’s dplyr) and DataFrames play an essential role.
While Pandas dataframes are inspired by R’s Dataframe structure, there are key differences beyond the programming languages. Notably, Pandas dataframes have indexes, whereas R Dataframes do not, which introduces different approaches to handling and manipulating data.
Importing pandas#
Pandas is a package, so to use it, we need to first import it.
It is very common to give Pandas the name alias pd:
import pandas as pd
Axis Labels#
Before diving into series and dataframes, it is important to understand that both data structures store data along axes (like in NumPy), but, these data also have labels along each axis. These axis labels are collectively referred to as the index.
Therefore, series and dataframes have:
An array that holds the data.
The ondexes that hold the labels for observations (rows) and features (columns).
Therefore, in contrast to NumPy, Pandas integrates identifible data in a natural way, making it easier to work with structured data.
Why we use an index?
It allows you to access elements in an array by name.
It enables series objects with shared index labels to be easily combined.
In fact, a dataframe is a collection of series with a common index.
To this collection of series the dataframe adds a set of labels along the horizontal axis.
The index is axis 0 or the rows.
The columns are another kind of index, called axis 1.
It is crucial to understand the difference between the index of a dataframe and its data in order to understand how dataframes work. Many errors stem from not understanding this difference.
Indexes are powerful and controversial.
They enable complex operations when accessing or combining data.
However, they can be costly in terms of performance and challenging to work with (especially multi-indexes).
Users coming from R might find Pandas dataframes behave differently than expected, leading to some confusion.
Below are some visuals to help:
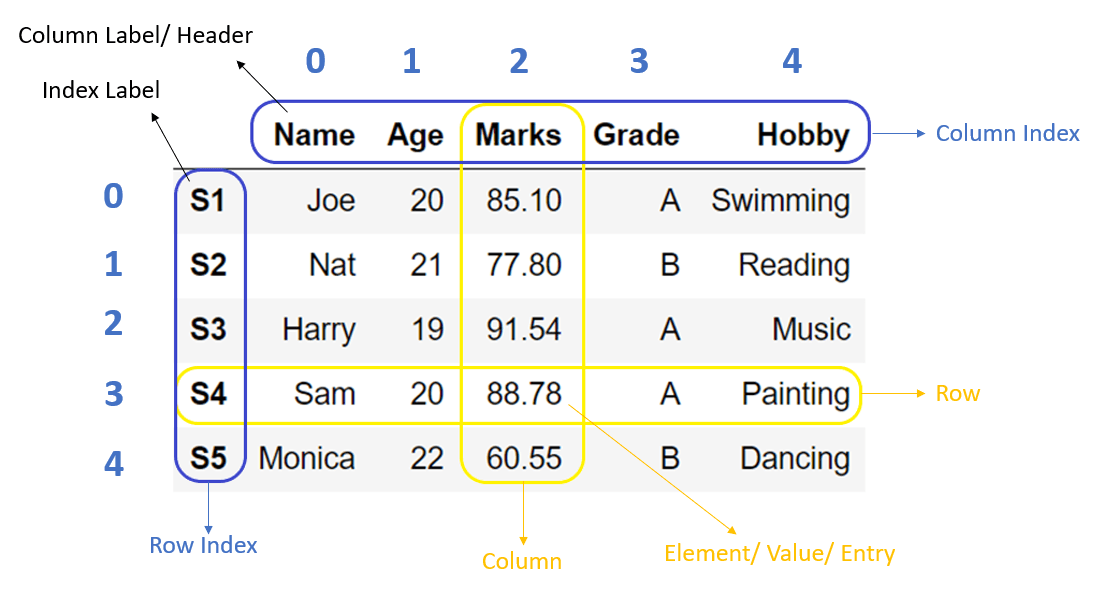
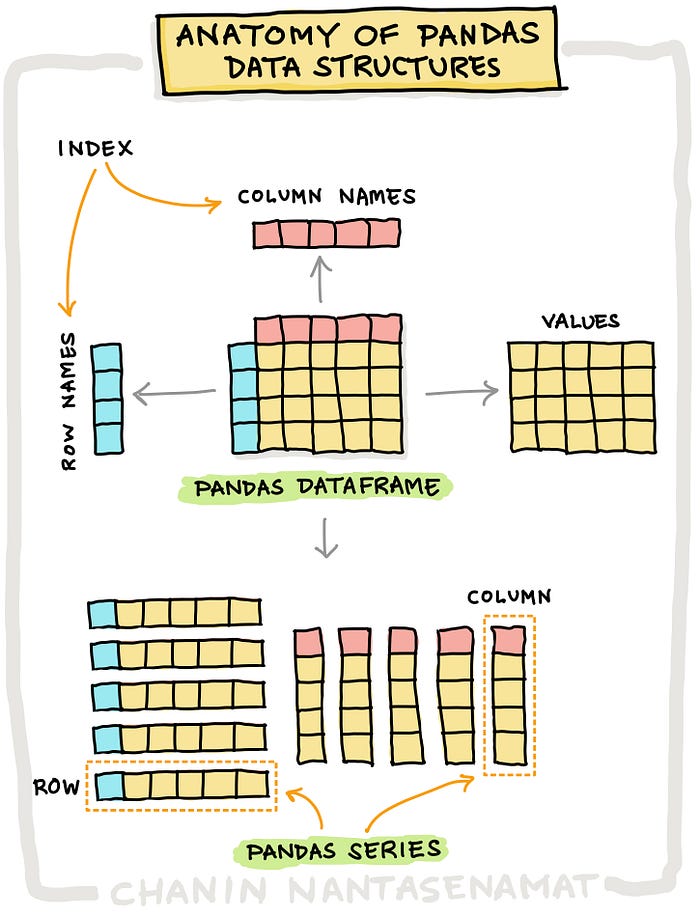
Series#
A series is essentially a one-dimensional array with labels along its axis. Its data must be of a single type, similar to NumPy arrays (which are used internally by Pandas).
The simplest way to create a series is by using the pd.Series() function.
How to create a series#
From a
list
data = [10, 20, 30, 40, 50]
series = pd.Series(data)
print(series)
0 10
1 20
2 30
3 40
4 50
dtype: int64
From a
dictionary
# Series from a dictionary
data_dict = {'a': 1, 'b': 2, 'c': 3}
series_dict = pd.Series(data_dict)
print(series_dict)
a 1
b 2
c 3
dtype: int64
Properties overview#
Indexing and slicing work similarly as with lists:
# Accessing elements in a Series
print(series[0]) # First element
print(series[1:3]) # Slicing
10
1 20
2 30
dtype: int64
It has methods and attributes:
# This attribute provides the series as numpy array
series.values
array([10, 20, 30, 40, 50])
# This two methods return the sum and mean
print(series.sum())
print(series.mean())
150
30.0
Data Frames#
As mentioned earlier, a dataframe is a two-dimensional labeled data structure with columns that can contain different data types. You can think of it as similar to an Excel table, where each column can store different types of data (e.g., numbers, text, or dates).
How to create a dataframe#
The simplest way to create a dataframe is by using the pd.DataFrame() function.
As dict of arrays or lists. This is the easiest and probably most common way, along with reading from a file:
# Creating a DataFrame from a dictionary
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, 27, 22, 32],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston'],
'Coffe Lover': [True, False, True, True]
}
df = pd.DataFrame(data)
df
| Name | Age | City | Coffe Lover | |
|---|---|---|---|---|
| 0 | Alice | 24 | New York | True |
| 1 | Bob | 27 | Los Angeles | False |
| 2 | Charlie | 22 | Chicago | True |
| 3 | David | 32 | Houston | True |
As a list of lists, where each list corresponds to one observation:
# Creating a DataFrame from a dictionary
data = [
['Alice', 24, 'New York', True],
['Bob', 27, 'Los Angeles', False],
['Charlie', 22, 'Chicago', True],
['David', 32, 'Houston', True]
]
df = pd.DataFrame(data)
df
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | Alice | 24 | New York | True |
| 1 | Bob | 27 | Los Angeles | False |
| 2 | Charlie | 22 | Chicago | True |
| 3 | David | 32 | Houston | True |
As you can see, if we only pass the data, Pandas will automatically assign sequential integers as labels for both axes (rows and columns).
However, we can customize this behavior by specifying our own labels when creating the dataframe:
index = ["obs1","obs2","obs3","obs4"]
columns = ['Name', 'Age', 'City', 'Coffe Lover']
df = pd.DataFrame(data, columns=columns, index=index)
df
| Name | Age | City | Coffe Lover | |
|---|---|---|---|---|
| obs1 | Alice | 24 | New York | True |
| obs2 | Bob | 27 | Los Angeles | False |
| obs3 | Charlie | 22 | Chicago | True |
| obs4 | David | 32 | Houston | True |
Alternatively, dataframes are objects, meaning they come with attributes and methods. The index and columns attributes allow you to retrieve the labels for axis 0 (rows) and axis 1 (columns) and redefine them if needed:
data = [
['Alice', 24, 'New York', True],
['Bob', 27, 'Los Angeles', False],
['Charlie', 22, 'Chicago', True],
['David', 32, 'Houston', True]
]
df = pd.DataFrame(data)
print(df)
df.index = index
df.columns = columns
print(df)
0 1 2 3
0 Alice 24 New York True
1 Bob 27 Los Angeles False
2 Charlie 22 Chicago True
3 David 32 Houston True
Name Age City Coffe Lover
obs1 Alice 24 New York True
obs2 Bob 27 Los Angeles False
obs3 Charlie 22 Chicago True
obs4 David 32 Houston True
From a file using, for example,
pd.read_csv:
pd.read_csv.__doc__.split("\n")[:15]
['',
'Read a comma-separated values (csv) file into DataFrame.',
'',
'Also supports optionally iterating or breaking of the file',
'into chunks.',
'',
'Additional help can be found in the online docs for',
'`IO Tools <https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html>`_.',
'',
'Parameters',
'----------',
'filepath_or_buffer : str, path object or file-like object',
' Any valid string path is acceptable. The string could be a URL. Valid',
' URL schemes include http, ftp, s3, gs, and file. For file URLs, a host is',
' expected. A local file could be: file://localhost/path/to/table.csv.']
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/refs/heads/master/iris.csv")
df
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
150 rows × 5 columns
By default, this function expects a file with comma-separated values (CSV). However, you have the flexibility to read files with different delimiters by specifying the sep parameter:
# Here columns were separated using tabular spaces
df = pd.read_csv("https://www4.stat.ncsu.edu/~boos/var.select/diabetes.tab.txt", sep="\t")
df
| AGE | SEX | BMI | BP | S1 | S2 | S3 | S4 | S5 | S6 | Y | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 59 | 2 | 32.1 | 101.00 | 157 | 93.2 | 38.0 | 4.00 | 4.8598 | 87 | 151 |
| 1 | 48 | 1 | 21.6 | 87.00 | 183 | 103.2 | 70.0 | 3.00 | 3.8918 | 69 | 75 |
| 2 | 72 | 2 | 30.5 | 93.00 | 156 | 93.6 | 41.0 | 4.00 | 4.6728 | 85 | 141 |
| 3 | 24 | 1 | 25.3 | 84.00 | 198 | 131.4 | 40.0 | 5.00 | 4.8903 | 89 | 206 |
| 4 | 50 | 1 | 23.0 | 101.00 | 192 | 125.4 | 52.0 | 4.00 | 4.2905 | 80 | 135 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 437 | 60 | 2 | 28.2 | 112.00 | 185 | 113.8 | 42.0 | 4.00 | 4.9836 | 93 | 178 |
| 438 | 47 | 2 | 24.9 | 75.00 | 225 | 166.0 | 42.0 | 5.00 | 4.4427 | 102 | 104 |
| 439 | 60 | 2 | 24.9 | 99.67 | 162 | 106.6 | 43.0 | 3.77 | 4.1271 | 95 | 132 |
| 440 | 36 | 1 | 30.0 | 95.00 | 201 | 125.2 | 42.0 | 4.79 | 5.1299 | 85 | 220 |
| 441 | 36 | 1 | 19.6 | 71.00 | 250 | 133.2 | 97.0 | 3.00 | 4.5951 | 92 | 57 |
442 rows × 11 columns
An introduction to some attributes and methods#
index,columns: Retrieve the row and columns labels.
df.index, df.columns
(RangeIndex(start=0, stop=442, step=1),
Index(['AGE', 'SEX', 'BMI', 'BP', 'S1', 'S2', 'S3', 'S4', 'S5', 'S6', 'Y'], dtype='object'))
We can also assign names to the axes, not just to the rows (observations) and columns (features):
df.index.name = 'obs_id'
df.columns.name = 'cols_id'
df
| cols_id | AGE | SEX | BMI | BP | S1 | S2 | S3 | S4 | S5 | S6 | Y |
|---|---|---|---|---|---|---|---|---|---|---|---|
| obs_id | |||||||||||
| 0 | 59 | 2 | 32.1 | 101.00 | 157 | 93.2 | 38.0 | 4.00 | 4.8598 | 87 | 151 |
| 1 | 48 | 1 | 21.6 | 87.00 | 183 | 103.2 | 70.0 | 3.00 | 3.8918 | 69 | 75 |
| 2 | 72 | 2 | 30.5 | 93.00 | 156 | 93.6 | 41.0 | 4.00 | 4.6728 | 85 | 141 |
| 3 | 24 | 1 | 25.3 | 84.00 | 198 | 131.4 | 40.0 | 5.00 | 4.8903 | 89 | 206 |
| 4 | 50 | 1 | 23.0 | 101.00 | 192 | 125.4 | 52.0 | 4.00 | 4.2905 | 80 | 135 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 437 | 60 | 2 | 28.2 | 112.00 | 185 | 113.8 | 42.0 | 4.00 | 4.9836 | 93 | 178 |
| 438 | 47 | 2 | 24.9 | 75.00 | 225 | 166.0 | 42.0 | 5.00 | 4.4427 | 102 | 104 |
| 439 | 60 | 2 | 24.9 | 99.67 | 162 | 106.6 | 43.0 | 3.77 | 4.1271 | 95 | 132 |
| 440 | 36 | 1 | 30.0 | 95.00 | 201 | 125.2 | 42.0 | 4.79 | 5.1299 | 85 | 220 |
| 441 | 36 | 1 | 19.6 | 71.00 | 250 | 133.2 | 97.0 | 3.00 | 4.5951 | 92 | 57 |
442 rows × 11 columns
values: Retrieves dataframe’s data as a numpy array:
df.values
array([[ 59. , 2. , 32.1 , ..., 4.8598, 87. , 151. ],
[ 48. , 1. , 21.6 , ..., 3.8918, 69. , 75. ],
[ 72. , 2. , 30.5 , ..., 4.6728, 85. , 141. ],
...,
[ 60. , 2. , 24.9 , ..., 4.1271, 95. , 132. ],
[ 36. , 1. , 30. , ..., 5.1299, 85. , 220. ],
[ 36. , 1. , 19.6 , ..., 4.5951, 92. , 57. ]])
type(df.values)
numpy.ndarray
copy(): gives the new df a clean break from the original. Otherwise, the copied df will point to the same object as the original.
df = pd.DataFrame({'x':[0,2,1,5], 'y':[1,1,0,0], 'z':[True,False,False,False]})
df_deep = df.copy() # deep copy; changes to df will not pass through
df_shallow = df # shallow copy; changes to df will pass through
print(hex(id(df)), hex(id(df_deep)), hex(id(df_shallow)))
0x7f442135e590 0x7f4426df3ed0 0x7f442135e590
dtypes: provides the types of each column:
df.dtypes
x int64
y int64
z bool
dtype: object
info(): prints information about the dataframe including the index dtype and columns, non-null values and memory usage.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 4 non-null int64
1 y 4 non-null int64
2 z 4 non-null bool
dtypes: bool(1), int64(2)
memory usage: 200.0 bytes
rename(): Renames columns or index labels. It can rename one or more fields at once using a dict, which acts as a mapper:
df.rename(columns={'z': 'is_label'}, index={2: "obs3"})
| x | y | is_label | |
|---|---|---|---|
| 0 | 0 | 1 | True |
| 1 | 2 | 1 | False |
| obs3 | 1 | 0 | False |
| 3 | 5 | 0 | False |
Note that to update the dataframe, you need to redefine the variable that stores it.
df
| x | y | z | |
|---|---|---|---|
| 0 | 0 | 1 | True |
| 1 | 2 | 1 | False |
| 2 | 1 | 0 | False |
| 3 | 5 | 0 | False |
df = df.rename(columns={'z': 'is_label'}, index={2: "obs3"})
df
| x | y | is_label | |
|---|---|---|---|
| 0 | 0 | 1 | True |
| 1 | 2 | 1 | False |
| obs3 | 1 | 0 | False |
| 3 | 5 | 0 | False |
Practice exercises#
Exercise 36
Create a dataframe called dat by passing a dictionary of inputs. Here are the requirements:
has a column named
featurescontaining floatshas a column named
labelscontaining integers 0, 1, 2
Print the df.
# Your answers from here
Exercise 37
Rename the labels column in dat to label.
# Your answers from here