Resilience
Table of contents
Resilience refers to a workflow’s ability to handle failures gracefully and recover automatically. Robust workflows anticipate and manage errors, timeouts, and unexpected conditions without requiring manual intervention.
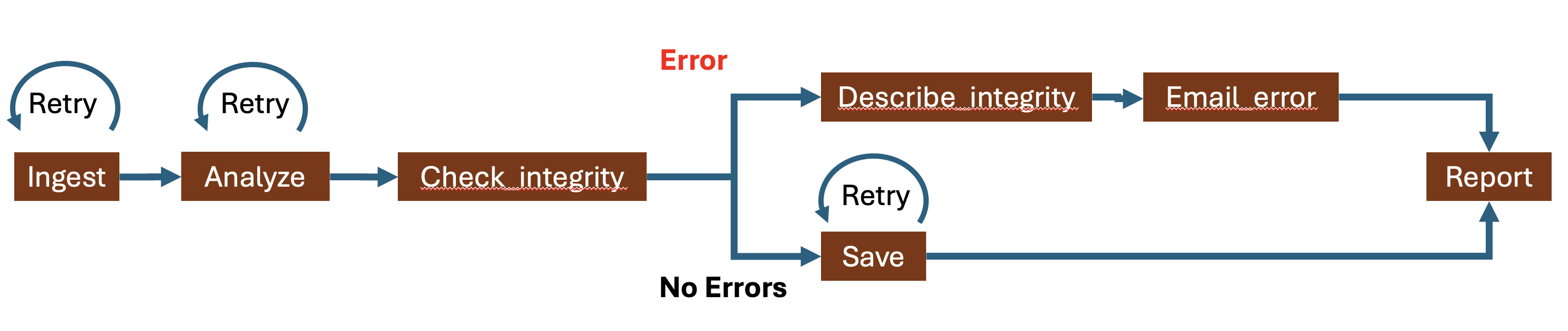
Exception Handling
Exception handling manages errors that occur during task execution. Workflows should catch and handle expected errors (e.g., missing data files, API rate limits) while allowing unexpected errors to propagate for debugging. Good exception handling includes logging error context, implementing fallback strategies where appropriate, and ensuring partial failures don’t corrupt the entire workflow’s state.
Timeouts
Timeouts prevent tasks from running indefinitely when they hang or take longer than expected. Setting appropriate timeout values ensures that stuck tasks don’t block the entire workflow and allows resources to be freed for other tasks. Timeouts can be set at the task level (individual task timeout) or workflow level (overall execution timeout), and should be configured based on expected execution times and resource availability.
Restarts
Automatic restarts enable workflows to recover from transient failures by retrying failed tasks. Such failures may include timeouts connecting to external sources, shutdown/reboot of the hardware infrastructure, etc. Restart strategies typically include configurable retry counts, exponential backoff delays between retries, and the ability to resume from the last successful checkpoint. When combined with effective caching (see Persistence), restarts can skip already-completed tasks and only re-execute failed or downstream tasks, making recovery efficient and cost-effective.