Orchestration
Organization of Tasks into Workflows
Tasks are the individual units of work often implemented as programmable function, or method of an class object, or even a standalone application. They represent discrete operations, such as extracting data, transforming it, or loading it into a database.
Workflows combine tasks into pipelines. The output of one task becomes the input to the next, creating a directed acyclic graph (DAG) of task dependencies. Most orchestrators allow the composition of nested workflows, providing even more flexibility to build complex processing pipelines from reusable smaller building blocks.

Orchestration, Execution, Scheduling
The orchestrator defines workflow structure and task dependencies, the execution engine runs tasks on available compute resources, and the resource scheduler manages and allocates compute resources (CPU, GPU, memory, storage) to meet workflow demands.
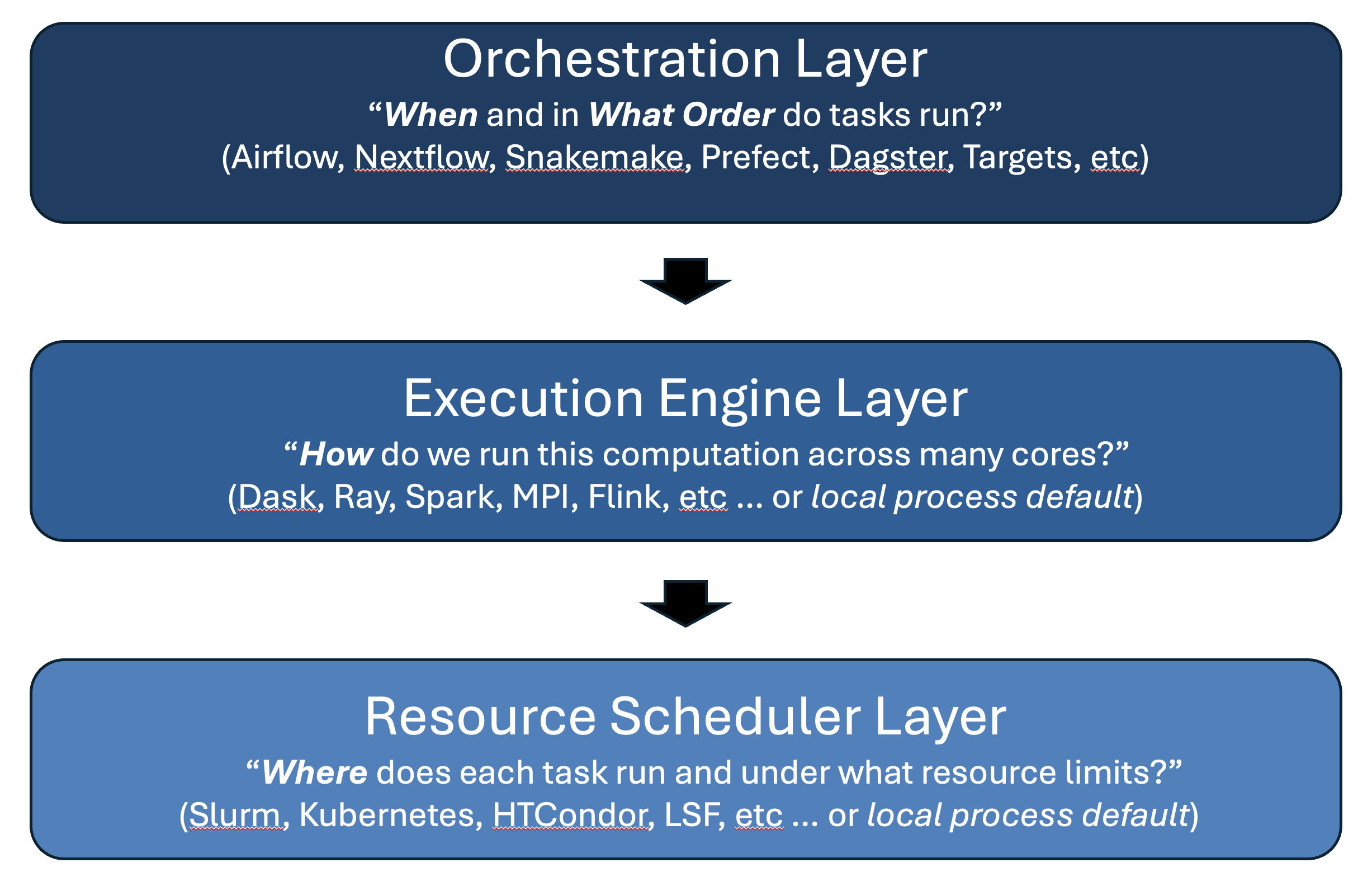
Distributed execution engines (Dask, Ray, Spark, MPI, etc.) enable scaling your pipeline to run across multiple computers (often referred to as nodes in a cluster). Resource schedulers are critically important in shared multi-user environments for managing access to limited compute resources. If you’re running your pipeline on your own computer, the execution engine and resource scheduling are handled by the operating system by default (as local processes), so you may not need the explicit separation into a three-layered framework. However, there can be benefits from a learning and prototyping standpoint. For example, running distributed execution engines like Apache Spark on a single node offers benefits related to ease of use, cost-effectiveness, and development consistency, especially for testing, learning, or working with datasets that exceed single-machine memory but aren’t at massive “big data” scale.