Use Cases
Table of contents
Devcontainers
A common issue in software development is working with a consistent environment with all dependencies. In Python development this usually means a specific version of the language, as well as numerous packages or libraries.
Devcontainers solve this challenge by integrating a container with a coding IDE. The IDE provides a strong graphical interface, support for extensions and plugins, and syntax highlighting, while the container provides a consistent environment re: software, paths, language, packages, and env variables, etc.:
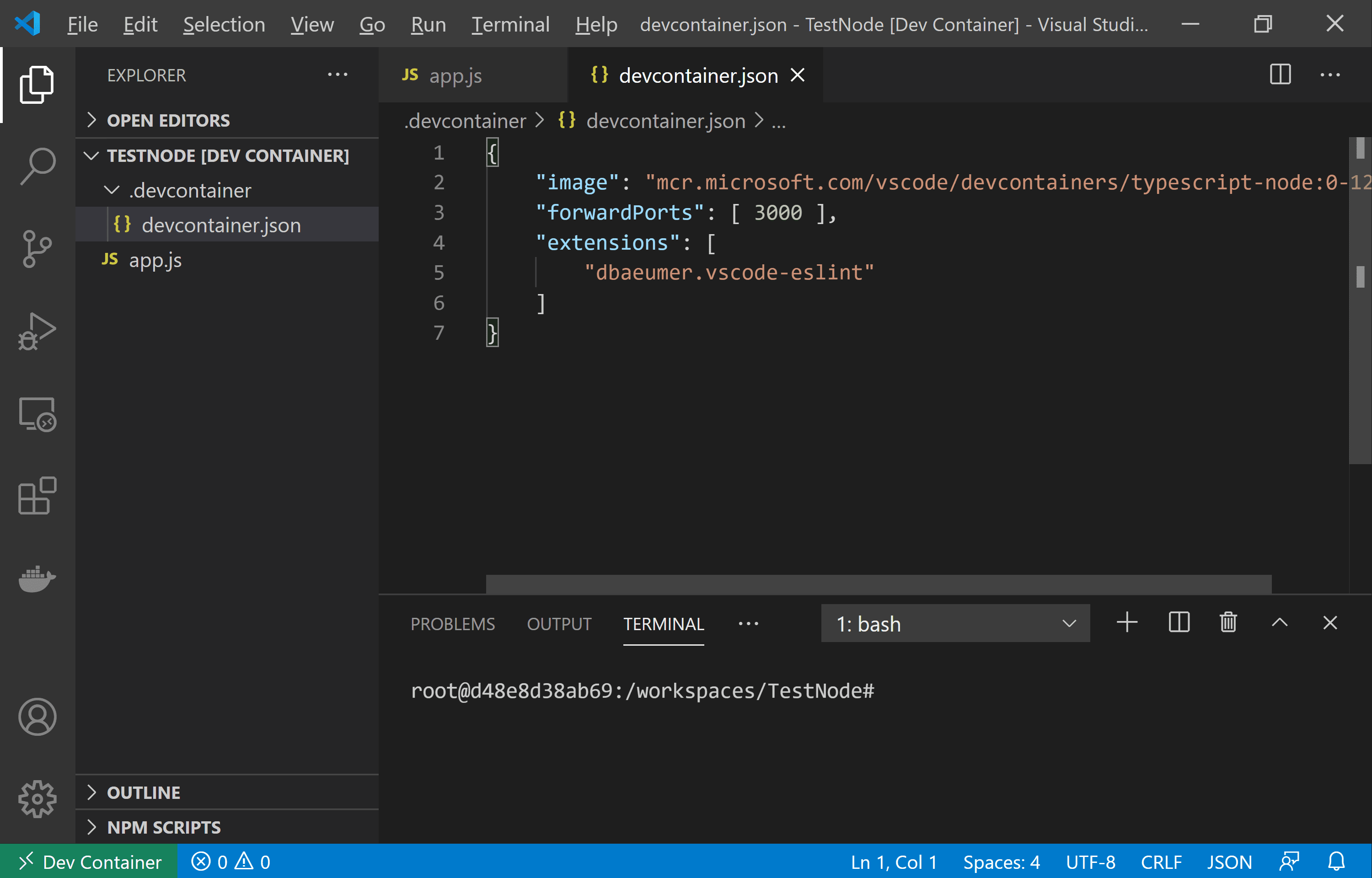
See this repository for more examples and instructions.
Learn More about Devcontainers at https://containers.dev/
Run a Script
One of the simplest use cases for containers is to run a process, or chain of updates or transformations against a data file.
In this example
Run a Service
Since containers are designed to perform a single operation well, it may be useful to run a service for lookups, references, or local testing.
Here we run a unique ID generator API on localhost port 8080 in detached mode. Once running the API is available at http://127.0.0.1:8080/
To fetch the API documentation, append /docs to the URL.
docker run -d -p 8080:80 ghcr.io/uvarc/id-generator:1.28
Access the API using a browser or the command-line, and pass the JSON through a filter like jq:
$ curl -s http://127.0.0.1:8080/keys | jq -r
{
"access_key": "UVJVZIMJAWPI",
"secret_key": "Hsibi1dR6As6RLNKqILIAaWPKG0T72Ra8ZNq"
}
$ curl -s http://127.0.0.1:8080/id/14 | jq -r
{
"id": "futcxiq2fllef6"
}
Pipeline Tasks
A variety of pipeline/workflow engines allow for the use of containers to peform individual tasks within a pipeline. For example, Apache Airflow, Dagster, and Prefect are all container-enabled. In most scenarios, the output of a previous task serve as input parameters for a containerized task (i.e. file location, task parameters, task options, output type).
Run a Database
Containers provide an ideal local database when testing code or a larger application. The local database can be seeded with test or example data to simulate the “real” production environment with live data.
Most databases can be launched locally with containers, including MySQL, PostgreSQL, MongoDB, Redis, and others.
Here we launch a single-node Redis in-memory datastore, available from the host machine over port 6379.
docker run -d --name redis -p 6379:6379 redis:latest
To connect using the Redis CLI:
redis-cli -h 127.0.0.1 -p 6379
The datastore is available as if it were a native service on the host machine. Keep in mind this deployment does not have persistent storage or any security associated with it. Restart the container and all data will be lost.
Launch a Service and Interface
Docker is also built to orchestrate the creation and management of multiple resources simultaneously, in a “stack”. This way, the entire stack is defined in a single piece of code, and can be started or stopped together as a whole.
In this use case, docker compose is used to launch a group of related resources to support a three-node clustser of Apache Kafka brokers, a Redpanda GUI to interact with the cluster, a private network across all containers in the solution, and persistent storage for each of the brokers.
docker-compose.yml
To run the stack, cd into the directory containing docker-compose.yml and issue this command:
docker compose up -d
You will see that a network and four (4) containers are spawned, and you can inspect each one using regular docker commands.
- Open a browser to http://127.0.0.1:8080/ to see the GUI.
- Point any Kafka producers or consumers to
internal://0.0.0.0:9092(other containers) orexternal://0.0.0.0:19092(other processes on the host machine).
To bring down the stack:
docker compose down
Learn More about Docker Compose at https://docs.docker.com/compose/
Play with Docker at https://labs.play-with-docker.com/
AWS Lambda
Lambda functions in AWS have typically run language-specific functions on demand, but since 2020 users have been able to bring their own containers instead. This allows developers to run a custom solution, older versions of software, shell scripts, and other unique software that requires a customized environment.
Container images in AWS Lambda may be up to 10GB in size, and will use most of the normal runtime parameters as a normal Lambda function: Both the event and context are passed to the container, as are environment variables, memory and CPU allocation, and execution duration.
For more about AWS Lambda BYOC refer to this documentation.
Google Cloud Platform - in GCP you can bring your own containers to Cloud Run, which brings together the former Cloud Functions and Cloud Run services under one service. Learn more.